
【EasyGPU】Lesson 1:认识 Kernel 与 Buffer

第一节:认识 Kernel 与 Buffer
前言:在本章节中我们不急于使用 EasyX,先通过一个简单的例子了解 EasyGPU 中的基本概念——核(Kernel)与缓冲(Buffer)。
在阅读本教程前,请确认你已了解:C++ 中的 lambda 函数,基础的 C++ 模板和 C++ 语法常识。
在配置好 EasyGPU 环境后,让我们输入测试代码:
#include <GPU.h>
#pragma comment(lib, "opengl32.lib") // 重要:EasyGPU 需要系统自带的 OpenGL 库,需要链接 OpenGL
int main() {
std::vector<float> input = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
Buffer<float> inputBuffer(input);
Kernel1D kernel([&](Int &X) {
auto boundBuffer = inputBuffer.Bind();
boundBuffer[X] += 1;
}, input.size());
kernel.Dispatch(1, true);
inputBuffer.Download(input);
for (auto& item : input) {
std::cout << item << " ";
}
return 0;
}如果正常编译运行,你将会得到如下结果:
1 2 3 4 5 6 7 8 9 10恭喜你!运行了你的第一个 GPU 计算程序!接下来就让我们对照这个初始例子来了解 EasyGPU 的基本概念。
在 EasyGPU 中编写程序的范式
两个世界:CPU 代码 vs GPU 代码
EasyGPU 是一个 Embedded DSL(嵌入式领域特定语言)库。这意味着你在 C++ 中编写的代码实际上会生成在 GPU 上运行的着色器程序。因此,你需要区分两种代码:
| CPU 代码 | 在编译期执行,使用 C++ 原生类型(int、float 等) |
| GPU 代码 | 在运行期生成着色器,使用 EasyGPU 提供的 GPU 类型 |
这种区分是理解 EasyGPU 的关键。当你在 Kernel Lambda 中写 Float a = 1.0f; 时,你并没有在创建 C++ 的 float 变量,而是在生成一段 GPU 运行的代码,声明一个 GPU 浮点变量并初始化为 1.0。
GPU 类型系统:Var 与 Expr
EasyGPU 提供了两类核心 GPU 类型:
| 类型 | 含义 | 类比 C++ |
| Var<T> | GPU 上的变量(可读可写,有存储) | int x; |
| Expr<T> | GPU 上的表达式(临时计算结果) | a + b |
Var<T> 和 Expr<T> 都继承自 Value,它们内部维护着 IR(中间表示)节点,用于生成最终的着色器代码。常见的类型别名如下:
using Float = Var<float>; // GPU 单精度浮点变量
using Int = Var<int>; // GPU 整型变量
using Bool = Var<bool>; // GPU 布尔变量
using Float2 = Var<Vec2>; // GPU 二维浮点向量
using Float3 = Var<Vec3>; // GPU 三维浮点向量
using Float4 = Var<Vec4>; // GPU 四维浮点向量
using Int2 = Var<IVec2>; // GPU 二维整型向量
// ... 以此类推与 C++ 字面量的混合运算
EasyGPU 的设计允许 GPU 类型与 C++ 字面量直接进行运算。这意味着你可以写出自然的数学表达式:
Float a = MakeFloat(1.5f);
Float b = a + 2.0f; // OK: Var<float> + float literal
Float c = 3.0f * a; // OK: float literal * Var<float>
Bool cond = a > 1.0f; // OK: 比较运算
Float3 pos = MakeFloat3(1.0f, 2.0f, 3.0f);
Float3 moved = pos + Float3(0.5f, 0.0f, 0.0f); // 向量与标量运算这里的 2.0f、3.0f 等是 C++ 的 float 字面量,它们会在编译期被捕获并转换为 GPU 的 uniform 常量。这是 EasyGPU 的便利之处——你不需要为字面量额外包装。
创建 GPU 值:MakeXXX vs ToXXX
当你需要主动创建 GPU 值时,必须使用 EasyGPU 提供的工厂函数,不能使用 C++ 的隐式转换或强制类型转换:
1. MakeXXX —— 包装字面量(无类型转换)
MakeFloat、MakeInt、MakeFloat3 等函数用于将 C++ 字面量包装成 GPU 类型。它们不进行任何类型转换,参数类型必须严格匹配:
Float f = MakeFloat(3.14f); // OK: float literal -> Var<float>
Int i = MakeInt(42); // OK: int literal -> Var<int>
Float3 v = MakeFloat3(1.0f, 2.0f, 3.0f); // OK: 三个 float -> Var<Vec3>
Float f2 = MakeFloat(42); // ERROR: 42 是 int,不是 float
Float f3 = (float)42; // ERROR: C++ 的强制转换不适用于 GPU 类型2. ToXXX —— 类型转换(执行转换操作)
ToFloat、ToInt 等函数用于在 GPU 类型之间进行显式类型转换:
Int i = MakeInt(42);
Float f = ToFloat(i); // OK: Var<int> -> Var<float>( widening conversion)
Float pi = MakeFloat(3.14f);
Int approx = ToInt(pi); // OK: Var<float> -> Var<int>(向零截断)
// 向量类型转换
Int3 iv = MakeInt3(1, 2, 3);
Float3 fv = ToFloat(iv); // OK: ivec3 -> vec3重要:不能使用 C++ 的 static_cast 或 C 风格强制转换来进行 GPU 类型转换:
Int i = MakeInt(42);
Float f = static_cast<float>(i); // ERROR: 编译通过,但行为错误!
Float f2 = (float)i; // ERROR: 同上完整示例:
Kernel1D kernel = [&](BufferView<float> input, BufferView<float> output) {
// 1. 从 Buffer 读取值(隐式创建 Expr<float>)
Float val = input[i];
// 2. 使用 MakeFloat 创建常量
Float scale = MakeFloat(2.0f);
// 3. 与 C++ 字面量混合运算
Float scaled = val * scale + 0.5f;
// 4. 需要类型转换时使用 ToXXX
Int index = ToInt(scaled); // float -> int(截断)
Float rounded = ToFloat(index); // int -> float
// 5. 写回 Buffer
output[i] = rounded;
};总结规则
| 场景 | 正确做法 | 错误做法 |
| 声明 GPU 浮点变量 | Float a; | float a; |
| 从 float 字面量创建 | MakeFloat(3.14f) | Float(3.14f)(构造函数被禁用) |
| 从 int 字面量创建 | MakeInt(42) | MakeFloat(42)(类型不匹配) |
| 类型转换 | ToFloat(intVar) | (float)intVar / static_cast<float>(intVar) |
| 与字面量运算 | var + 1.0f(无需特殊处理) | / |
| 创建向量 | MakeFloat3(1.0f, 2.0f, 3.0f) | Float3(1, 2, 3)(整数类型不匹配) |
理解这一点:Var<T> 和 Expr<T> 不是数据的容器,而是着色器代码的生成器。每一次赋值、每一次运算,都是在构建 GPU 程序的 IR 树。这正是 EasyGPU 作为 Embedded DSL 的本质所在。
EasyGPU 还有其他与直接使用 C++ 书写的代码的区别,我们会在接下来的教程中为大家详细解释清楚。
核(Kernel)
什么是 Kernel?
想象你要让 GPU 帮你做 10000 道相同的数学题。Kernel 就是你给 GPU 的"解题说明书"——它定义了**每一道题**应该怎么算。
在 EasyGPU 中,Kernel 是 GPU 计算的入口。你可以把它理解为一个特殊的函数,这个函数会被 GPU 同时执行成千上万次,每一次处理不同的数据。
一维、二维、三维 Kernel
根据你要处理的数据维度,EasyGPU 提供了三种 Kernel 类型:
| 类型 | 适用场景 | 例子 |
| Kernel1D | 一维数据 | 数组、音频采样点、粒子列表 |
| Kernel2D | 二维数据 | 图片、纹理、二维网格 |
| Kernel3D | 三维数据 | 体素、三维纹理、三维空间 |
怎么选择?看你的数据是什么形状:
- 处理一列数字 → Kernel1D
- 处理一张图片(有宽和高) → Kernel2D
- 处理一个三维空间(有 x, y, z) → Kernel3D
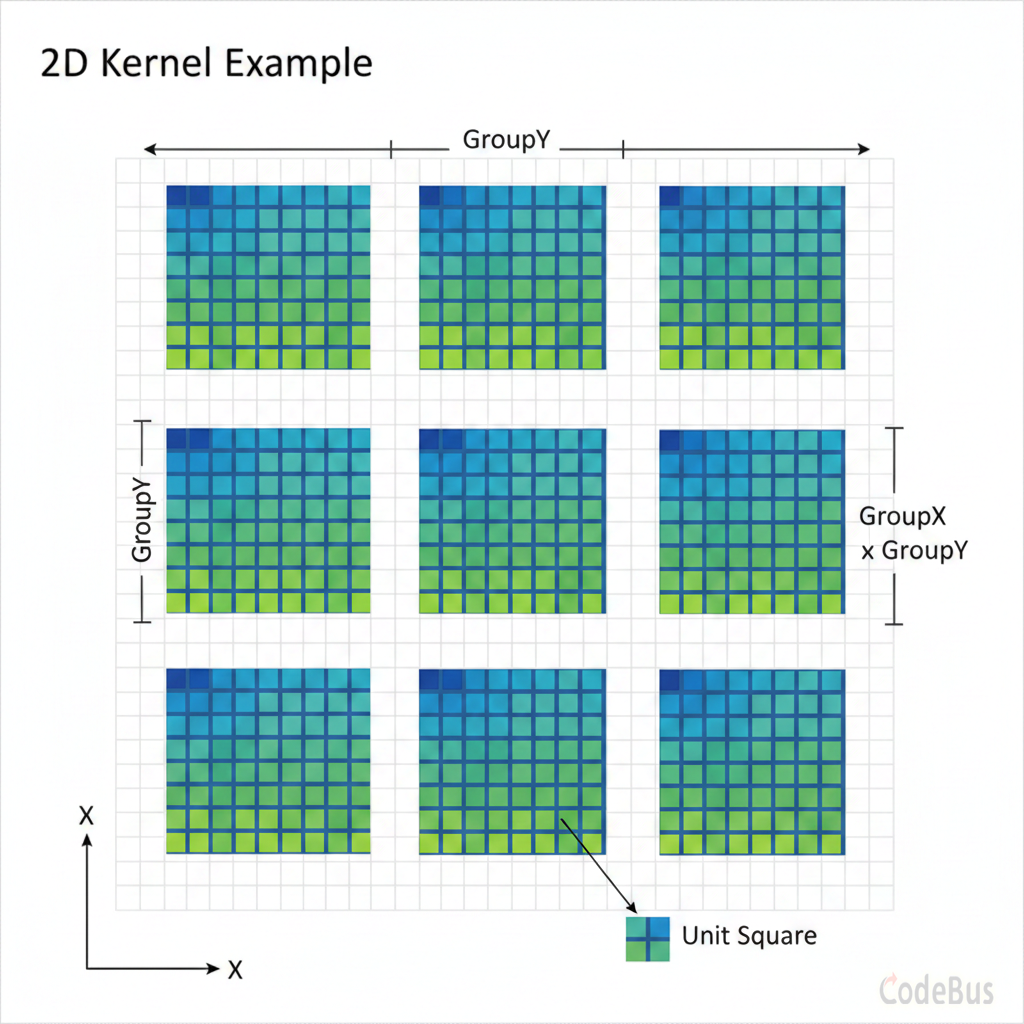
工作组(Work Group):GPU 的"小组分工"
GPU 在执行 Kernel 时,会把所有任务分成若干个工作组(Work Group)。这就像学校大扫除:
- 整个学校 = 所有要处理的数据(比如整张图片的所有像素)
- 每个班级 = 一个工作组(Work Group)
- 每个学生 = 一个工作项(Work Item,即一次 Kernel 调用)
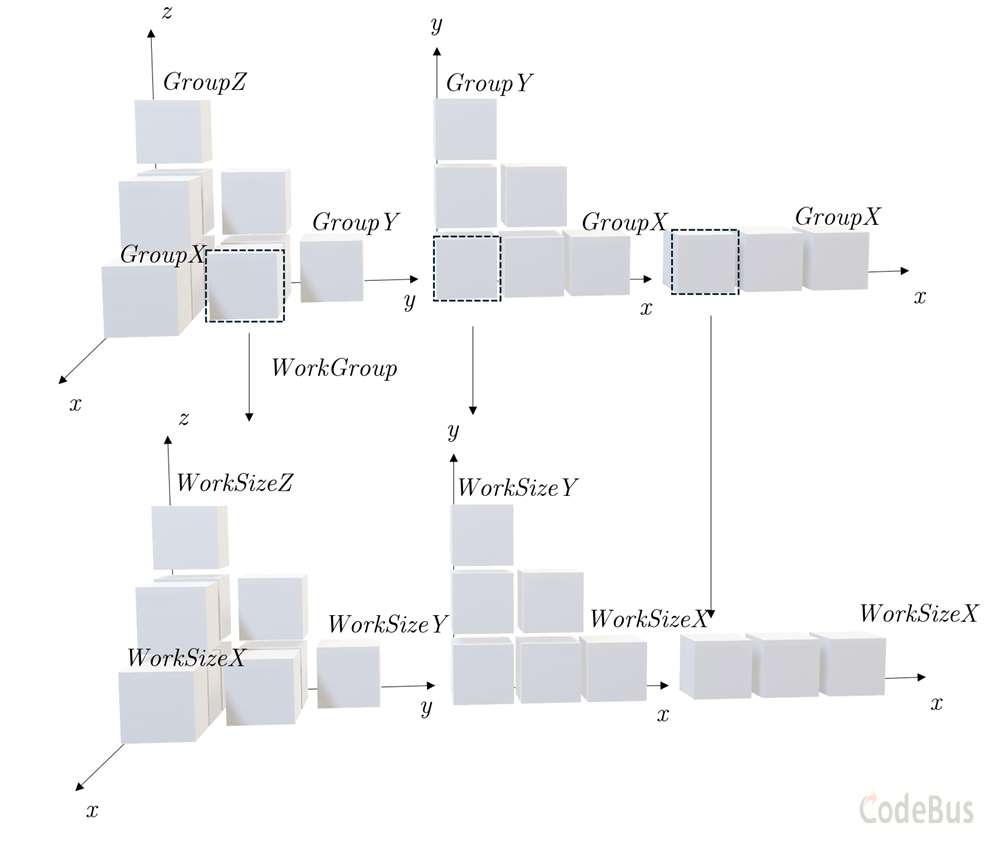
为什么要分组?因为同一个工作组内的"学生"(工作项)可以:
- 共享一块快速的局部内存 Local Memory)
- 互相同步(Sync)
局部 ID vs 全局 ID
每个"学生"有两个身份标识:
| ID 类型 | 含义 | 类比 |
| 局部 ID | 在当前工作组内的编号 | "我是 3 班的 5 号" |
| 全局 ID | 在所有任务中的编号 | "我是全校第 89 号" |
以 Kernel2D 为例:
全局坐标 (Global ID): 你在整个图片中的位置 $(x, y)$
局部坐标 (Local ID): 你在当前工作组内的位置 (localX, localY)
工作组 ID: 你在哪个工作组 (groupX, groupY)
代码示例
Kernel1D:处理一维数组
// 创建一个处理 1024 个元素的 1D Kernel
Kernel1D kernel([&](Int x) {
// x 是当前元素的全局索引 [0, 1023]
auto buf = buffer.Bind();
buf[x] = buf[x] * 2.0f; // 每个元素乘以 2
}, buffer.size()); // 总大小:1024指定工作组大小(可选)
默认情况下,EasyGPU 会自动选择工作组大小。但你可以手动指定(通常是 64、128、256 等 2 的幂):
// 1024 个元素,每组 128 个线程,共 8 组
Kernel1D kernel([&](Int x) {
// ...
}, 128); // 工作组大小 128
kernel.Dispatch(1024, true); // 总大小 1024Dispatch 函数
每个 Kernel 都提供了 Dispatch 函数,用于将 Kernel 提交给 GPU 运行,需要指定 WorkGroup 的大小,如:
kernel.Dispatch(1024, true);上述代码将 Kernel1D 以 1024 个工作组大小提交给 GPU 运行。第二个参数 sync 决定代码行为:sync=true 表示等待 GPU 计算完成后继续执行后面的代码,sync=false 表示不等待 GPU 计算完成,直接继续执行后面的代码。
假如你设置了 sync=false,在之后依然可以使用 kernel.RuntimeBarrier(); 函数进行堵塞操作(“等待 GPU 计算完成”):
Kernel1D kernel([&](Int &X) {
auto boundBuffer = inputBuffer.Bind();
boundBuffer[X] += 1;
}, input.size());
kernel.Dispatch(1, false);
kernel.RuntimeBarrier();Buffer
在 EasyGPU 中,提供了 Buffer<T> 作为与 GPU 进行数据交流的媒介之一。简单来讲 Buffer<T> 就是一个 GPU/CPU 互通的数组,正如示例代码一样,你可以通过 std::vector 来直接创建一个 Buffer<T>:
std::vector<float> input = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
Buffer<float> inputBuffer(input);或者是你可以指定 Buffer<T> 的元素大小来创建一个 Buffer:
Buffer<float> buffer(30);Buffer<T> 提供了三种读写模式:
Buffer<float> buffer(input, BufferMode::Read); // 只读
Buffer<float> buffer(input, BufferMode::Write); // 只写
Buffer<float> buffer(input, BufferMode::ReadWrite); // 可读可写假如不显式指定 BufferMode,则默认为 BufferMode::ReadWrite(可读可写)。
在创建了 Buffer<T> 以后,你依然可以通过 Upload 函数再次向 Buffer<T> 中提交数据:
std::vector<float> input = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
buffer.Upload(input);同样支持指针传入数据:
float *ptr = new float[size];
buffer.Upload(ptr, size);在 Kernel 中,你不能直接操作 Buffer<T> 对象,需要对 Buffer 进行绑定操作:
auto boundBuffer = inputBuffer.Bind();获得一个 Buffer 在 GPU 中的实例 BufferRef<T>,BufferRef<T> 重载了 [] 运算符,可以使用 [] 对数据进行读写,如:
Kernel1D kernel([&](Int &X) {
...
boundBuffer[X] += 1; // 读写
Float a = MakeFloat(boundBuffer[X]); // 读取
}, input.size());值得特别注意的是,如果需要把 BufferRef<T> 赋值给一个变量,必须显式地进行 MakeFloat 操作,否则得到的变量默认是一个指向 Buffer<T> GPU 显存的"指针",而非一个独立的含值变量。
在 Kernel 的 Dispatch 方法运行完后,可以通过 Download 方法将 GPU 计算好的数据重新下载到内存中:
inputBuffer.Download(input);Download 的其他重载与 Upload 相似,此处不再赘述。但值得注意的是:**Download 必须在 GPU 已经计算完数据后运行**。
课后作业
1. 试阐述 Kernel、Work Group 与 Work Item、Buffer 的概念,检验自己对基础概念的理解。
2. 试着使用 Kernel2D 与 Buffer 尝试构建一个二维的计算程序。
答案
1. 略
2.
#include <GPU.h>
#pragma comment(lib, "opengl32.lib")
int main() {
std::vector<float> input = {
0, 1, 2, 3,
4, 5, 6, 7,
8, 9, 10, 11
};
int width = 4;
int height = 4;
Buffer<float> inputBuffer(input);
Kernel2D kernel([&](Int& X, Int &Y) {
auto boundBuffer = inputBuffer.Bind();
boundBuffer[Y * width + X] += 1;
}, 2);
kernel.Dispatch(2, true);
// Or use
// kernel.Dispatch(2, 2, true);
inputBuffer.Download(input);
int index = 0;
for (auto& item : input) {
std::cout << item << " ";
++index;
if (index % width == 0) {
std::cout << std::endl;
}
}
return 0;
}
添加评论
取消回复